Inteligencia Artificial (IA)
Resumen IA: Google Deep Think, OpenAI Spark y M2.5
5 min de lectura
15.02.2026
Noticias clave de IA: Google Deep Think rompe benchmarks, OpenAI lanza Spark en Cerebras y MiniMax presenta M2.5, además de guías y herramientas.
Resumen diario de IA: Google, OpenAI, MiniMax y más
Buenos días, {{ first_name | AI enthusiasts }}. OpenAI y Anthropic han acaparado los titulares de 2026, pero Google vuelve a recordar por qué es una potencia clave en la carrera de la IA. Con una mejora de su modo de razonamiento Deep Think que bate benchmarks en matemáticas, codificación y ciencia, y un nuevo agente de investigación capaz de resolver problemas abiertos de forma autónoma, Google empuja la investigación en IA hacia nuevos territorios.
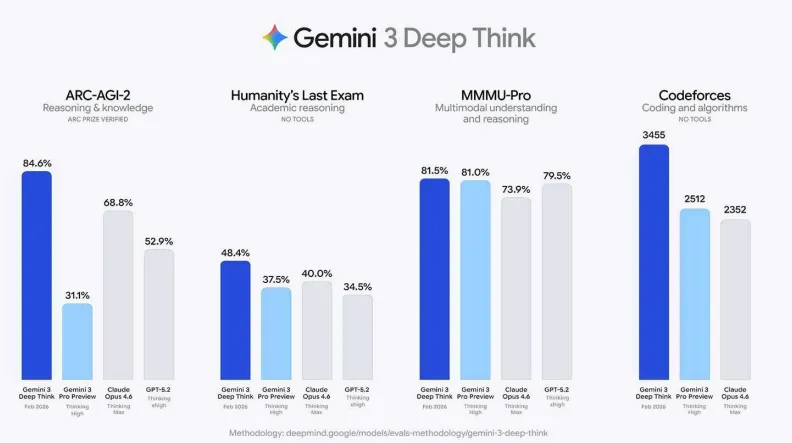
Google: Deep Think domina benchmarks de razonamiento
Deep Think alcanza puntuaciones récord en matemáticas, codificación y ciencia; Aletheia, el nuevo agente matemático, verifica demostraciones y resuelve problemas abiertos.
El resumen: Google actualizó Deep Think (Gemini 3) y obtuvo resultados líderes en múltiples benchmarks académicos y de programación. La actualización incluye un agente de investigación matemática que verifica demostraciones y supera marcas previas en benchmarks de dominio.
- Resultados destacados: 84,6% en ARC-AGI-2 (frente a Opus 4.6 con 68,8% y GPT-5.2 con 52,9%) y 48,4% en el Examen Final de la Humanidad.
- Medallas de oro en Olimpiadas de Física y Química 2025; Elo de 3.455 en Codeforces, casi 1.000 puntos por encima de Opus 4.6.
- Aletheia: agente matemático autónomo para demostrar y verificar resultados complejos.
- Disponibilidad: actualización en la app Gemini para suscriptores Google AI Ultra; API en acceso anticipado para investigadores.
Por qué importa: estas mejoras mueven la frontera en matemáticas y ciencias, y señalan que Google sigue siendo un actor dominante en investigación de IA, además de empresas centradas en aplicaciones comerciales.
OpenAI: modelo de codificación ultrarrápido en chips Cerebras
GPT-5.3-Codex-Spark ofrece más de 1.000 tokens/s en hardware Cerebras, priorizando velocidad para flujo interactivo de desarrollo.
El resumen: OpenAI lanzó GPT-5.3-Codex-Spark, optimizado para velocidad sobre Cerebras, como primer producto fuera de la pila Nvidia de la compañía.
- Rendimiento: Spark sacrifica algo de calidad frente al Codex completo en benchmarks SWE-Bench Pro y Terminal-Bench, pero acelera tareas drásticamente.
- Estrategia de chips: acuerdo de más de $10.000M con Cerebras y contratos con AMD y Broadcom para diversificar hardware.
- Disponible como vista previa para suscriptores ChatGPT Pro; API limitada a socios empresariales inicialmente.
Por qué importa: la codificación en tiempo real con retroalimentación instantánea puede transformar flujos de trabajo de desarrollo, y la diversificación de hardware es clave en la estrategia de infraestructura de IA.
Guía práctica: generar un anuncio de televisión con IA
El resumen: aprende a crear un anuncio de 20 segundos con apariencia profesional usando modelos generativos y herramientas de video.
- Idea y storyboard: pide a Gemini que planifique dos escenas de 5 segundos.
- Genera prompts para cuadros iniciales y finales de cada escena.
- En Higgsfield (requiere plan): Imagen > Crear Imagen > Nano Banana Pro, calidad 4K, 4 variaciones, ratio 21:9. Genera y descarga cuadros clave.
- En Video > Kling 3.0 sube cuadros y genera clips; une los clips en un editor gratuito.
- Consejo: pide términos fotográficos ("toma heroica") y genera música con Suno + Eleven Labs.
Voxel51: reduce el coste de etiquetado de datos
Evita etiquetar datos redundantes: pipelines basados en retroalimentación pueden ahorrar tiempo y dinero mientras mejoran el rendimiento.
El resumen: el taller técnico de Voxel51 (18 de febrero) enseña a construir pipelines de anotación eficientes que eliminan etiquetado innecesario.
- Técnicas cubiertas: selección sin-shot y uso de embeddings, flujos de QA focalizados, conjuntos de prueba para detectar drift y depuración con embeddings.
MiniMax: M2.5, modelo de codificación de frontera y bajo coste
M2.5 iguala a Opus 4.6 y GPT-5.2 en benchmarks de codificación, pero con costes por salida mucho menores.
El resumen: MiniMax lanzó M2.5, un modelo con rendimiento de codificación competitivo y precios que lo hacen viable para agentes 24/7.
- APIs: M2.5-Lightning (más rápido, $2.40/salida) y M2.5 estándar ($1.20/salida) — significativamente más baratos que Opus ($25/salida).
- Uso interno: M2.5 gestiona ~30% de tareas diarias y 80% de nuevos commits en MiniMax.
- Disponibilidad: API pública; pesos y licencia de código abierto aún no publicados.
Por qué importa: la reducción de costes por salida facilita desplegar agentes autónomos a gran escala y cambia las decisiones de adopción en la industria.
Otras noticias relevantes
- ByteDance publica Seedance 2.0 (modelo SOTA para videos virales) con acceso restringido.
- Mustafa Suleyman (FT): predicción de automatización masiva de trabajos de cuello blanco en 12–18 meses.
- Elon Musk sobre salidas en xAI y reestructuración por velocidad de ejecución.
- OpenAI retira GPT-4o, GPT-4.1 y o4-mini de ChatGPT; debate de la comunidad sobre preservación de modelos.
- Anthropic anuncia financiación de $30.000M valorada en $380.000M con ingresos crecientes, impulsados por Claude Code.
- Investigadora Zoë Hitzig renuncia a OpenAI por preocupaciones sobre manipulaciones y uso de datos.
Flujos de trabajo de IA de la comunidad
Cada edición destaca cómo los lectores usan la IA para ahorrar tiempo. Hoy: Anthony H. (Australia) construyó un escáner de códigos QR en iPad con Google AI Studio, GitHub y Vercel para gestionar miembros y preservar la privacidad local de datos.
¿Cómo usas la IA? Cuéntanos aquí.
Nos vemos pronto — Rowan, Joey, Zach, Shubham y Jennifer, el equipo humano detrás de The Rundown.
Comentarios
Sin comentarios
Agregar Comentario